How Whiskers Works
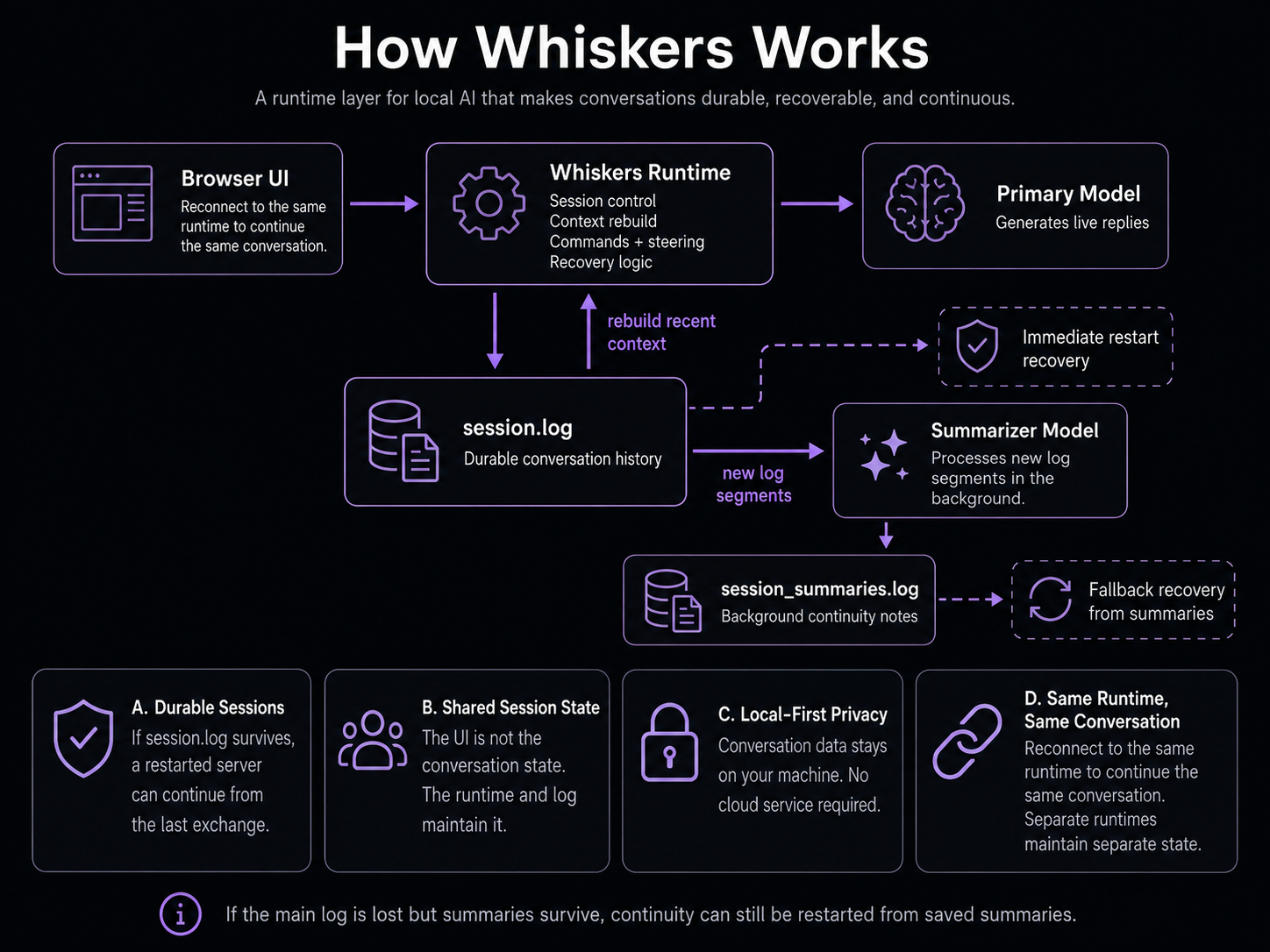
Whiskers is a runtime layer for local AI: it keeps durable state outside the model, then feeds the model bounded recent context when it responds.
Not Another Chatbot
Whiskers does not replace your local model. It sits between the browser UI and the model server, adding persistence, logging, commands, context control, and background summarization.
The model still generates the text. Whiskers controls the session around it.
Runtime Flow
Whiskers keeps the conversation state outside the model. The model handles replies, while the runtime manages persistence, context rebuilds, and background summaries.
The primary model handles the live conversation. Whiskers writes each interaction to session.log, rebuilds the recent context window from that log, and sends that context back into the primary model on later turns. Separately, the summarizer model reads new log entries and writes compressed summaries to session_summaries.log.